

- Align formats and fields across sources to avoid mismatches and enable smooth system integration.
- Implement strong data validation processes to detect inaccuracies and enhance reliability.
- Enrich and update data continuously to reflect real-time changes and support better decision-making.
Table of Contents
B2B decision making depends on data. But for data aggregators, keeping that data clean is a daunting task. For data aggregators, there are several sources to collect information ranging from websites, public records, forms, and APIs. However, each source comes with its own set of errors and complexities. This makes it tough to ensure accuracy, remove duplicates, or fill gaps. And so, poor data quality has grown into one of the biggest challenges faced by businesses across the globe. According to a study conducted by Gartner, bad data costs businesses an average of $12.9 million each year. And the number keeps growing as companies seemingly rely on larger datasets with little oversight.
More data does not mean better quality or insights. In the absence of the right checks, more data often leads to more chaos and confusion. Data aggregators need clear methods to manage data, validate sources, maintain consistency and keep data fresh.
The role of data aggregation in B2B data quality
In the B2B ecosystem, data aggregation is the term used to describe the process of collecting data from CRMs, marketing automation platforms, public databases, sales engagement tools and third-party vendors. Without aggregation, this data remains siloed. The aggregation process effectively aligns naming conventions, fills in missing fields, removes redundancies, and links to related records, resulting in a unified view of leads, accounts, and customer behavior.
Aggregated data lays the groundwork for targeted marketing, effective lead scoring, and personalized outreach, making it foundational to all high-performing B2B sales and marketing efforts.
Why do B2B data aggregators face data quality challenges
There are multiple challenges including structural, semantic, and operational, when it comes to data aggregation from different B2B channels and when done at scale. Data aggregators often find themselves dealing with inputs that vary greatly in quality, format, and reliability. Without strong systems to check and standardize this information, a bunch of problems happen later on, especially in areas related to segmentation, analytics, and engagement.
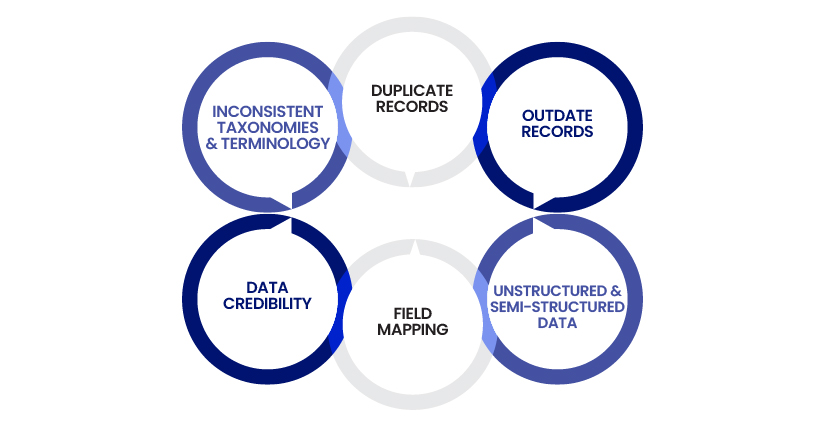
Here are some of the major challenges that B2B data aggregators often face
- Inconsistent taxonomies and terminology: Different sources might label the same thing in various ways. This lack of a shared language makes it difficult to make reliable comparisons.
- Duplicate records: Sometimes, small differences in company names or addresses can create what looks like separate entries. These duplicates can muddy insights and distort reports.
- Outdate records: Data freshness also poses problems. Outdated information can lead to poorly targeted outreach and wasted efforts.
- Data credibility: Aggregators often pull data from unknown sources, making it very difficult to determine the accuracy of data.
- Field mapping: Incompatibility between field mapping with different units, ranges, or definitions results in inaccuracy.
- Unstructured and semi-structured data inputs: B2B data comes from PDFs, scraped web content, or APIs with no schema. This creates further complexity in cleansing and integration.

Data aggregation combines information from diverse sources
- Manual methods can’t solely ensure quality of aggregated data.
- Automated error detection improves precision and data quality.
- Combining ML with verification and validation ensures data reliability.
- ML models automate error detection, creating scalable workflows.
Top 5 proven strategies to improve B2B data quality
Keeping your B2B data accurate is important for reaching the right people, making informed decisions, and driving growth. Bad data can mean lost chances and wasted effort. Here are five practical tips to help you tidy up your data, improve results, and give your team the confidence to act on useful insights.
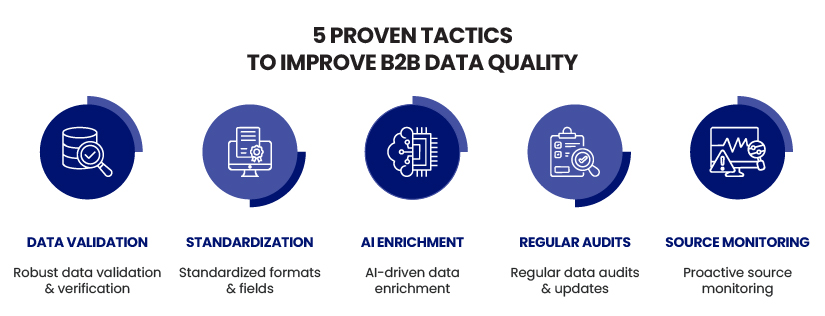
1. Implement robust data validation and verification
Reliable and accurate data is the core of B2B data quality. This makes data validation a crucial aspect in ensuring correct and credible data. However, data validation happens to be the most overlooked aspect in aggregation. When invalid or inaccurate entries go unchecked, the result is poor lead quality, damaged reputation and wasted resources across sales & marketing. Even minor errors such as mistyped email addresses or domains, incorrect phone numbers, inconsistent entries and wrong job titles lead to poor segmentation or failed campaigns.
In order to overcome these errors, data validation should be considered an intrinsic part of the aggregation process and not an afterthought.
- Check if the email looks correct and if the domain is real by looking up its MX record. Verify phone numbers against carrier databases and make sure they follow local formats.
- Cross-check data with trusted sources like LinkedIn, Crunchbase, or D-U-N-S numbers to confirm that everything is legit.
- Use automated tools to verify the data in real time, flagging any suspicious entries and fixing typos.
- Assign a score to each record, helping to prioritize reliable ones without needing to double-check everything manually.
2. Standardize data formats and fields
In B2B data aggregation, inconsistencies don’t just slow things down; they create friction across every system that touches the data. Aggregators often collect the same type of information from multiple sources, but the structure, naming conventions, and field values vary widely. Without standardization, you end up with records that can’t be matched, merged, or used effectively.
Here are steps to standardize data format and fields
- Create a data source audit: Learn about your company’s data sources. Standards are effective only if they account for all data realities. Key steps include understanding the kind of data, how frequently each data source is updated and whether the data source is a third party source or not.
- Define data format: Data needs and sources are different. Each and every company has a different requirement. Data standards should be specific, so you leave no data behind in your business systems; they should hold up even if there’s a flood of rapid, disparate information. Standards should be relevant for today’s data as well as data you may have in future.
- Standardize existing data in the database: Implement best practices to apply the same standards to data already collected. Data filtering allows the refining of data sets to include only that needed for a specific task or campaign and exclude data that is repetitive, irrelevant, or sensitive.
Are data errors costing you leads and revenue?
Explore how better data quality fuels smarter decisions and better results.
3. Leverage AI and machine learning for data enrichment
Even the most structured B2B datasets are often incomplete. Records may have basic identifiers like company name and email, but lack deeper attributes such as employee count, tech stack, industry classification, or revenue range. Without these, segmentation suffers, lead scoring weakens, and personalization becomes guesswork. AI and machine learning (ML) offer a scalable way to fill these gaps, improve accuracy, and future-proof data pipelines.
AI-driven enrichment uses pattern recognition and predictive modeling to enhance raw records with additional relevant fields. Rather than relying on manual research or static databases, these systems can infer, and update information based on context, similarity, and real-world signals.
Here are some everyday examples of how AI and machine learning can enhance data management:
- Firmographic completion: Think about it; for instance, there is a record that includes a domain name only. AI models can analyze that domain, connect it to business directories, and update useful details such as company size, revenue, number of locations, and industry type.
- Technographic inference: By scanning public websites, AI can figure out the tech stack of companies such as CRM tools, cloud services, or marketing automation platforms. This helps businesses reach out more effectively based on what tools they’re compatible with.
- Predictive role of intelligence: If you have a person’s email and domain but don’t know their job title, AI can make a good guess based on common naming conventions and similar profiles.
- Real-time updates: Machine learning can spot when certain information is outdated, like if a job title or company name doesn’t match current trends. It can alert you to necessary updates or checks.
Beyond just filling gaps, AI works to keep data up to date, identify errors, and can even help categorize accounts automatically into segments or verticals, making the data management process much smoother.
4. Schedule regular data audits and updates
Research reports indicate that nearly 30% of B2B data becomes outdated every year. For data aggregators, this means that even data that pass all validation checks can become obsolete in the coming years. This makes routine data audits and updates an integral part of maintaining data quality in the long term. Data audits identify a host of issues ranging from detecting silent errors, identifying stale fields, and uncovering patterns of errors.
Practical approaches to scheduling audits:
- It is very important to pay attention to how rapidly things change. For instance, if you are dealing with details like job titles and phone numbers in areas such as tech startups, data is constantly changing, you might want to check every month. Data in the government or public sector might not change at a fast pace.
- Automate the process of flagging records that might be out of date, like those with missing information or bounced emails. Setting up a system to pull in fresh data can save time.
- Use feedback from customer interactions to figure out which segments require a recheck. If lots of emails are bouncing or going unopened, it’s a sign that those records might need to be verified again.
- Maintain a log indicating when each field or record was last updated or validated to prioritize refresh and important to ensure compliance audits and vendor accountability.
5. Monitor and manage data sources proactively
The quality of aggregated B2B data is only as good as the sources it comes from. Cleaning the data after it enters is no longer enough. Instead, aggregators need to make data governance a primary function.
Key practices to monitor and manage data
- Create a performance benchmark for each data source. Track metrics such as cost per unit, time to produce, product/service quality, time to market, customer satisfaction & loyalty, and brand recognition.
- Remove or replace low-quality sources proactively. Don’t wait for client complaints or poor campaign results. If a vendor or feed routinely introduces noise or formatting issues, it’s often more efficient to phase it out.
- Pay attention to the frequency of updates such as weekly, daily, or biweekly. If a provider sends outdated data or stops updating it, your data might lose value.
- Create automatic checks to help track major structural changes that drop important information and impact your data quality.
How clean data drives better B2B success
Data hygiene is a key differentiator in B2B ecosystems. Inaccurate or outdated data introduces risk at every stage of the buyer’s journey. Several aspects ranging from targeting, segmentation to forecasting are directly impacted by data quality. Data accuracy helps improve decision making, sales numbers, and team alignment with goals.

Here’s how clean data contributes to B2B success:
- Precise segmentation: Clean data helps businesses focus on the right set of audiences. When marketing teams have access to the right information, they can define their ideal customer profiles, which saves resources by staying clear of leads that don’t match their needs.
- Faster sales process: Reliable data leads to a faster sales process. Sales reps can reach out to the right people instead of worrying about bounce-back emails or outdated job titles. Sales pipelines move faster and improve the chances of closing deals.
- Enhanced lead scoring: High-quality data enhances lead scoring efforts, as it allows teams to identify promising leads, ultimately increasing conversion rates.
- Accurate forecast: Forecasts based on accurate data are much more trustworthy, giving finance and leadership teams confidence in their planning. Plus, clean data cuts down on manual corrections, making operations smoother and less costly.
- Compliance & security: Clean data reduces manual corrections and ensures compliance with data protection laws like GDPR and CCPA.
Conclusion
Ensuring B2B data quality is an ongoing process. It’s an ongoing effort vital to every strategic choice, from marketing to sales and customer support. The return on investing in clean, reliable B2B data is measurable. This translates into better segmentation, lead conversion, pipeline accuracy, and customer relationships.
Regular investment in data quality frameworks, governance models and tools are a business requirement and foundation of B2B success. That’s why partnering with a specialized data aggregation company can steer businesses ahead of the curve. This partnership offers useful tools and a dedicated team of aggregators to handle data from start to finish. This helps keep your data reliable as your business grows, allowing your team to concentrate on planning and expanding.
Tired of fixing broken data?
Hire data aggregation experts who get it right the first time.




