

- Real estate data cleaning involves standardizing addresses, validating property details, handling missing data, and conducting thorough consistency checks.
- Advanced strategies include using ML for outlier detection, geospatial data validation, data clustering, predictive modeling and active learning to ensure real estate data accuracy.
- Collaboration, continuous improvement, and a strong focus on data consistency are crucial for maintaining clean and reliable real estate data.
Accurate real estate data is the key to making informed decisions about everything in real estate, from property valuations to client interactions. However, ensuring real estate data accuracy is a constant challenge.
Table of Contents
- Real Estate Data Cleaning Challenges
- The Adverse Effects of Inaccurate Real Estate Data
- Basic Real Estate Data Cleaning Strategies
- Advanced Strategies to Ensure Real Estate Data Accuracy
- Machine Learning for Anomaly Detection
- Clustering for Data Consistency Checks
- Predictive Modeling for Missing Data Imputation
- Natural Language Processing (NLP) for Data Extraction
- Geospatial AI for Location Data Cleaning
- Active Learning for Targeted Manual Review
- Automated Data Validation Rules
- Ensemble Techniques for Robust Data Cleaning
- The Way Forward
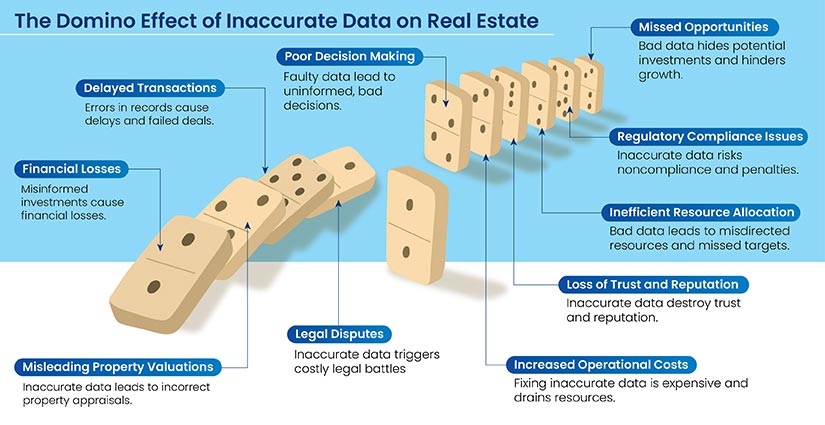
Issues like human errors, outdated information, and the complexity of integrating data from multiple sources lead to inaccuracies in the data. This causes financial losses and leads to inefficient operations and damaged reputations, unless the issues are addressed at the source.
Real estate data cleaning is the process through which we identify and rectify errors, inconsistencies, and outdated information in the data, thus increasing its reliability. This enables stakeholders to make better decisions, improve customer experiences, and gain a competitive edge in real estate marketing.
But cleaning real estate data has its own set of challenges. Here, we take a look at the challenges of maintaining clean data, explore strategies for data cleaning and management, and discuss the impact it has on real estate businesses.
Real Estate Data Cleaning Challenges
It’s a hard task to maintain clean real estate data primarily due to the variety of sources it comes from. Some of the key challenges include:
- Non-standard data formats: Real estate data vary widely in structure and format between different sources. Trying to merge this information while maintaining accuracy and consistency requires high expertise and appropriate infrastructure.
- Data subjectivity: Real estate descriptions often rely on subjective terms (e.g., “charming,” “cozy”), making it difficult for users to compare and analyze properties. People also have varying opinions on property conditions and neighborhood desirability. This lack of objective standards makes it hard to quantify real estate data, creating inconsistencies and inaccuracies in listings and valuations.
- Data fragmentation: This data is collected from a wide range of sources, such as MLS, government records, private databases, and other places. This results in a fragmented and incomplete picture of the real estate landscape, making it difficult for non-experts to consolidate and integrate information.
- Dynamic and evolving market conditions: The real estate market is constantly changing, with property values, availability, and other details fluctuating regularly. Keeping data up to date in real time is challenging and requires constant monitoring and updates from different sources.
- Geographic and locational nuances: Real estate is tied to location, and requires handling of geospatial data like property boundaries, zoning regulations, and proximity to amenities.
- Data misrepresentation risks: Real estate data is prone to misrepresentation due to communication errors, technical glitches, lack of verification, and misinterpretation of non-standard terminologies where present.
Enhance your real estate decision-making with accurate data
Transform unstructured text into actionable insights with our expert services
The Adverse Effects of Inaccurate Real Estate Data
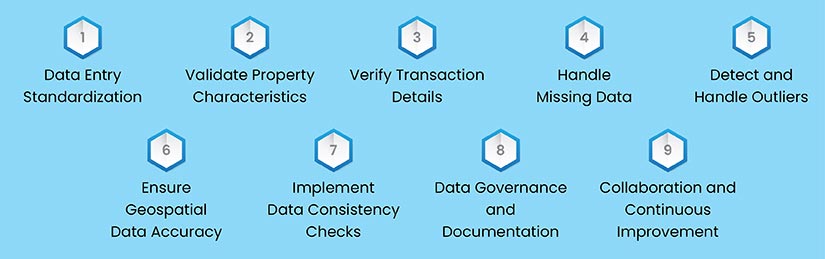
Basic Real Estate Data Cleaning Strategies
Ensuring real estate data accuracy starts with getting it right from the beginning. We do this by identifying reliable sources like government records, MLS listings, and reputable real estate websites. We use real estate data collection techniques to capture the information.
After initial gathering of the data, we decide on which data cleaning strategies to use to standardize formats, handle missing values, correct errors, and remove duplicates. By applying data validation techniques and real estate domain knowledge, we further enhance accuracy. Additionally, identifying and addressing outliers refines the data even further.
Data cleaning is an ongoing process, not a one-time fix. The real estate market changes quickly, so our data must be frequently cleaned to ensure accuracy.
Data Entry Standardization
The process of keeping your real estate data clean and consistent starts with standardizing the data entry process. This means that everyone uses the same formats, terms, and validation rules. This simple strategy helps ensure better MLS data hygiene by minimizing errors, inconsistencies, and duplicate entries.
For example, techniques such as address validation or geospatial mapping standardize property addresses. This makes geocoding more accurate and allows location-based analysis. By separating addresses into individual fields (street number, street name, city, state, zip code), it’s easier to clean and match the data.
Validating Property Characteristics
To ensure our property data is accurate, we cross-check details such as square footage, lot size, number of bedrooms/bathrooms, and amenities against trustworthy sources like MLS listings, county assessor records, and building permits. Through regular data verification, we make sure the database stays accurate and up to date.
We identify and resolve discrepancies using standard rules or manual review by domain experts. We also implement data quality checks to make sure property characteristics align with what’s typical for the property type and location.
Verifying Transaction Details
We check sales prices, dates, and involved parties against official county documents, transfer tax records, and title data. Annotators flag any missing or inconsistent information for review and correction. They validate that sale prices match reasonable ranges for the location and property type and confirm temporal consistency in transaction histories.
Handling Missing Data
Patterns of missing data need to be analysed to decide if it is missing completely at random (MCAR), missing at random (MAR), or missing not at random (MNAR).
If it’s MCAR, simple imputation techniques like using the mean or median will do the trick. If it is MAR, then multiple imputation is a practical choice. And if it’s MNAR, we’ll need to use our domain knowledge to impute the missing values.
Detecting and Handling Outliers
Employing statistical outlier detection methods tailored for real estate data, such as median absolute deviation (MAD) or Hampel identifier, is the way to identify anomalous property values, rental rates, or other metrics.
We use these methods to investigate flagged outliers and determine whether they are genuine anomalies or data errors requiring correction. Use domain expertise to assess the plausibility of extreme values in the real estate context.
Ensuring Geospatial Data Accuracy
We need to validate the positional accuracy of property coordinates by comparing them against authoritative geospatial datasets or by conducting field surveys. This is done to attribute accuracy by cross-referencing property characteristics with geospatial data sources. We need to check for temporal consistency in geospatial data and update records to reflect changes over time.

How to leverage online Clustering Algorithms and APIs to tackle fluctuating volumes in real estate data aggregation
- MLS APIs and web scraping together enhance the accuracy of real estate listings.
- Clustering APIs provide direct access to MLS data, web scraping captures additional information.
- The combination ensures comprehensive, current property details, improving data quality.
Implementing Data Consistency Checks
We use automated tools to continuously monitor real estate datasets for inconsistencies, such as mismatched property types and zoning classifications, invalid date ranges, or inconsistent units of measurement. For this, we configure data quality rules and alerts to flag potential issues for review and resolution. Real estate domain experts use their knowledge to define and refine consistency checks.
Data Governance and Documentation
Data scientists develop clear data governance policies and procedures that outline roles, responsibilities, access levels, permissions, and processes for ensuring better property data management. We have to document all data standards, validation rules, and cleaning procedures to ensure consistency and reproducibility. Maintaining data lineage to track sources, transformations, and dependencies of real estate datasets is a key priority here.
Collaboration and Continuous Improvement
Engaging real estate domain experts throughout the data cleaning process helps leverage their knowledge and insights. We establish feedback loops and communication channels to facilitate continuous improvement of data quality practices.
Review is done regularly, and we frequently update data cleaning techniques, methods, and strategies to adapt to changing real estate data landscapes and business requirements.
Scalable, flexible and robust data aggregation model ensures a high performing property database of 7M+ records for a USA-based real estate investment and property management company
HitechDigital helped a USA-based real estate company collect 9,000+ property data daily from various sources. HitechDigital addressed the challenge of maintaining data accuracy for the high data volume by creating a team of specialists trained in extracting data from complex documents.
Read full Case Study »Advanced Strategies to Ensure Real Estate Data Accuracy
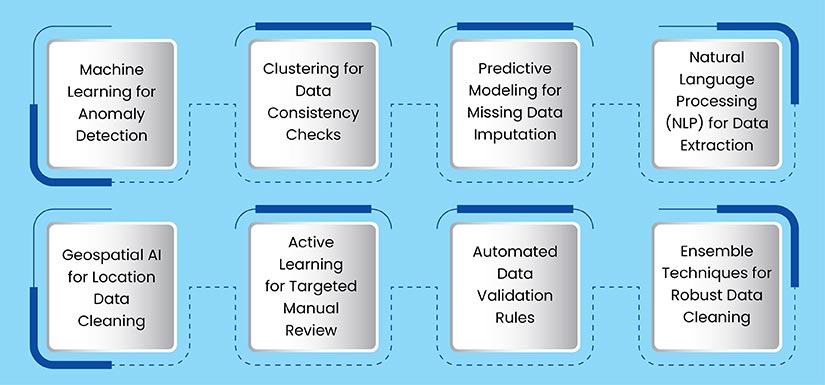
Due to the sheer volume and complexity of the data involved, we need advanced strategies leveraging AI and ML to ensure real estate data accuracy. Valuable property data often comes in unstructured form and it is difficult to standardize and extract insights with only basic techniques.
ML algorithms spot patterns and anomalies that we might overlook, making sure the data is on point. Natural Language Processing (NLP) uses unstructured text data, such as property descriptions, to augment structured databases. AI-powered image recognition examines property photographs to assess their condition and validate them against listing information.
Predictive models can also predict property values, which helps validate data and spot outliers. Combining these advanced techniques improves data accuracy, enabling better decision making in the real estate domain.
Machine Learning for Anomaly Detection
Machine learning algorithms like Isolation Forest, Local Outlier Factor, and One-Class Support Vector Machines automatically identify anomalies and outliers in real estate datasets. These include unusual property values, transaction prices, or rental rates that may indicate data errors or fraudulent activities.
Clustering for Data Consistency Checks
Clustering algorithms such as K-means and DBSCAN help in grouping similar properties based on location, size, age, and other features. This helps identify inconsistencies in property characteristics within clusters, allowing for targeted data cleaning efforts.
Predictive Modeling for Missing Data Imputation
Classification models like Decision trees and Random forests predict missing or inconsistent data points based on patterns learned from complete records. This enables automated imputation of missing property features, transaction details, and other variables.
Natural Language Processing (NLP) for Data Extraction
NLP techniques extract structured information from unstructured text data like property descriptions, automatically categorizing property types, amenities, and conditions. This helps standardize and enrich real estate datasets for accurate property listing.
For example, NLP extracts “3 bedrooms, 2 bathrooms, renovated kitchen” from a listing description, enabling accurate filtering and comparison of properties based on specific criteria. This automation reduces manual errors and inconsistencies, leading to more reliable real estate data.
Geospatial AI for Location Data Cleaning
Geospatial AI uses methods such as geocoding standardization, spatial clustering for outlier detection, and validation against authoritative datasets to clean real estate location data. It also employs address parsing and fuzzy matching techniques to handle inconsistencies and errors.
Geostatistical methods like Kriging and Spatial Interpolation can estimate property values missing location data points, such as property coordinates or neighborhood characteristics based on spatial patterns.
Improve your real estate marketing campaigns
Target the right audience with our precise real estate data targeting solutions.
Active Learning for Targeted Manual Review
We use active learning algorithms to iteratively identify the most informative data points for manual review by domain experts. This targeted approach optimizes the use of human expertise, ensuring that corrections are made where they matter most. Over time, the model learns from these corrections, iteratively improving its accuracy.
For example, if a model struggles to distinguish between “condo” and “apartment” listings, Active Learning will present these cases to human reviewers. With each correction, the model gets better at classifying these property types, ensuring accurate search results and property details.
Automated Data Validation Rules
AI is also used to define and enforce data validation rules specific to real estate, such as checking if property types match zoning classifications, sale prices fall within expected ranges, and historical data is temporally consistent.
Ensemble Techniques for Robust Data Cleaning
Combining multiple AI models using ensemble methods like stacking or boosting can improve the overall accuracy and robustness of the data cleaning process, leveraging the strengths of different techniques.
Increased circulation reach for periodical publisher in real-estate through accurate data aggregation
HitechDigital helped a US-based real estate publisher increase circulation by aggregating accurate property data. The client needed data from various sources to create targeted marketing campaigns. HitechDigital’s team captured and cleansed data from MLS sites, county websites, and property documents. A multi-layered quality check ensured data accuracy.
Read full Case Study »The Way Forward
Implementing these strategies, techniques, and processes helps professionals ensure real estate data accuracy through clean and reliable data. This enables more informed decision-making, reduces risk, and boosts data-driven insights in the real estate domain.
As the industry continues to move forward, the volume and complexity of data will only increase. Strategizing with these advanced technologies is more than staying competitive; it’s about leveraging the benefits of clean real estate data for enhanced customer experiences, and ultimately, a more efficient and transparent real estate market.
Thus, by prioritizing data quality and investing in advanced data cleaning strategies, real estate professionals can pave the way for a data-driven future that benefits all stakeholders.
Optimize your property data collection
Enhance your real-estate data processes with our expert solutions.




