

- Quality control metrics are essential for creating accurate AI training data through text annotation.
- The five key metrics used are precision, recall, F1-score, accuracy, and inter-annotator agreement (IAA).
- Best practices for using these metrics include aligning metric selection with the annotation task, continuous monitoring and combining metrics with qualitative analysis.
High quality text annotation is important for preparing accurate training data for building AI models and to help them understand and process human language in a better way. However, ensuring the accuracy and reliability of annotated data requires stringent quality control.
Table of Contents
To ensure quality control in text annotation, you need to conduct iterative evaluation and improvement of the annotated dataset. This is done by professional text annotators by assessing annotations against quality control metrics.
Metrics like precision ensure that the identified annotations are truly relevant. Recall assesses the ability to find all relevant instances, minimizing the number of missed annotations. F1-score provides a balanced view of performance, combining precision and recall into a single metric.
Inter-annotator agreement (IAA) measures the consistency between different annotators. The accuracy metric measures the overall correctness of the annotations, including both positive and negative predictions.
By using these five key text annotation metrics, annotators create the high-quality training data needed for successful NLP and AI model development.
Why Quality Matters in Text Annotation
High-quality text labeling helps to accurately reflect the nuances of human language, leading to more robust and reliable models. Conversely, poor-quality annotations introduce noise into the training data, which can propagate through the model and result in inaccurate predictions.
Consider text annotation for sentiment analysis, a common NLP task. If the training data is rife with inconsistencies or errors in sentiment labeling, the resulting model risks misinterpreting sarcastic or ironic language, leading to erroneous sentiment predictions. This leads to negative impacts, especially in applications such as social media monitoring or brand reputation management.
Inaccurate annotations cause costly rework and disruptions in project timelines. In healthcare and legal domains, where accuracy is crucial, the consequences of poor annotation quality is even more severe.
What are the metrics used to measure text annotation quality
Let’s break down the five key metrics that provide crucial insights for refining guidelines and training annotators, and thus, help in improving text data labeling accuracy.
Quality Metric 1: Precision
Precision in text annotation measures the proportion of correctly annotated items, out of the total number of items annotated as positive. In simpler terms, it answers the question, “Of all the instances we identified as belonging to a particular class, how many were actually correct?”
It is calculated as:
Precision = True Positives / (True Positives + False Positives)
High precision is crucial when the cost of false positives is high. For instance, in a legal document review system, incorrectly identifying a non-contractual clause as a contractual obligation could have significant legal ramifications.
Quality Metric 2: Recall
Recall, also known as sensitivity or the true positive rate, quantifies the ability of an annotation model to identify all relevant instances within a dataset. It addresses the question, “Of all the actual instances belonging to a particular class, how many did we manage to identify?”
Recall is calculated as:
Recall = True Positives / (True Positives + False Negatives)
High recall is critical when it’s crucial to minimize false negatives. In a medical diagnosis system, for example, failing to identify a critical symptom could have severe consequences.
Enhance Your AI Models
Leverage our expert text classification and categorization services
Quality Metric 3: F1-Score
Precision and recall often have a trade-off. Improving one can sometimes hurt the other. The F1 score helps to find a balance. It serves as a harmonic mean of precision and recall, providing a balanced assessment of a model’s performance.
It is calculated as follows:
F1-score = 2 * (Precision * Recall) / (Precision + Recall)
The F1-score is particularly useful when there is an uneven class distribution (i.e., class imbalance) in the dataset. In such scenarios, a model might achieve high precision by focusing on the majority class while exhibiting poor recall of the minority class. The F1-score helps mitigate this issue by considering both precision and recall equally.
The following table illustrates the impact of precision and recall on the F1 score:
The F1-score is a valuable metric in text annotation for NLP because it provides a single, interpretable score that reflects both the precision and recall of a model.
Understanding Precision, Recall and F1-Score through an illustrative example
Consider annotating a news article to identify people’s names (Named Entity Recognition).
Here’s a sample sentence from the article:
Globex CEO Tom Carter announced a new product at this year’s product launch event in California
Annotation ground truth (correct annotations):
Tom Carter
The model’s annotations:
Tom Carter
California (incorrect)
Parameters for the metrics:
- True Positives (TP): Correctly identified entities (Tom Carter in this case)
- False Positives (FP): Entities incorrectly identified (California)
- False Negatives (FN): Entities missed by the model (None)
Metric 1 – Precision: How accurate are the positive predictions?
Formula: TP / (TP + FP)
In our example: 1 / (1 + 1) = 0.5
Interpretation: 50% of the entities that the model identified were correct.
Metric 2 – Recall: How many of the actual entities did the model find?
Formula: TP / (TP + FN)
In our example: 1 / (1 + 0) = 1
Interpretation: The model found 100% of the people’s names.
Metric 3 – F1 Score: A balanced measure combining precision and recall.
Formula: 2 * (Precision * Recall) / (Precision + Recall)
In our example: 2 * (0.5 * 1) / (0.5 + 1) = 0.67
Interpretation: Provides a single score summarizing both precision and recall.
Low-precision NER models may mislabel locations or organizations as people, while low recall can miss identifying key individuals in text.
Quality Metric 4: Accuracy
Accuracy represents the proportion of correctly classified instances (both positive and negative) out of the total number of instances.
It is calculated as:
Accuracy = (True Positives + True Negatives) / (True Positives + True Negatives + False Positives + False Negatives)
True Positives (TP): Correctly identified positive instances.
True Negatives (TN): Correctly identified negative instances.
False Positives (FP): Incorrectly identified positive instances (Type I error).
False Negatives (FN): Incorrectly identified negative instances (Type II error).
High accuracy indicates a well-performing model. A high number of false positives will lower precision and overall accuracy. A high number of false negatives will decrease recall and potentially the overall accuracy.
While accuracy provides a general sense of model performance, it is essential to consider precision, recall and F1-score alongside accuracy, particularly when dealing with imbalanced datasets or when the cost of different error types varies significantly.
Add Context to Your Data
Gain clarity with our expert semantic annotation.
Quality Metric 5: Inter-Annotator Agreement and Consistency
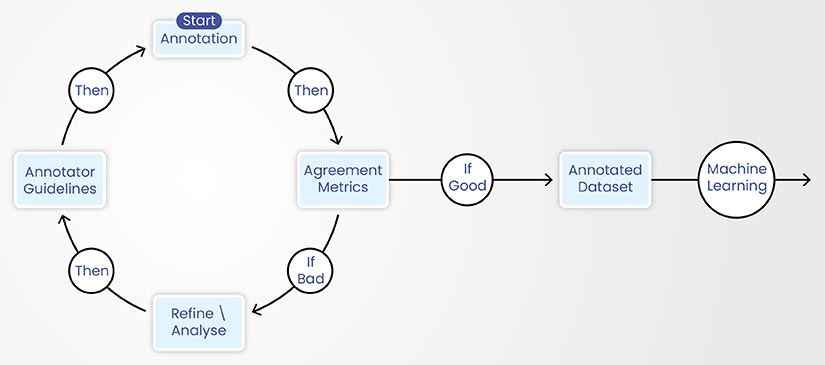
Inter-annotator agreement (IAA) measures the level of consensus among multiple annotators on a given annotation task. It is a crucial aspect of text annotation quality control, as it helps to assess the reliability and consistency of the annotations. High IAA indicates that the annotation guidelines are clear and well understood, leading to more reliable and trustworthy annotated data.
Several statistical measures are commonly used to quantify IAA:
Cohen’s Kappa (κ): A popular metric for measuring agreement between two annotators on categorical data. It considers the possibility of agreement occurring by chance, making it more robust than simple percentage agreement.
Fleiss’ Kappa: This extension of Cohen’s Kappa allows for the assessment of agreement among three or more annotators. It is useful when multiple annotators are involved in the annotation process.
The Kappa values are interpreted as follows:
Gwet’s AC2: It addresses some of the limitations of Cohen’s Kappa, particularly against imbalanced category distributions. AC2 remains reliable, even if some categories are much more frequent than others in the annotated data.
Krippendorff’s Alpha (α): A more general measure of agreement that can handle different data types, including nominal, ordinal, interval and ratio data. It is also suitable for situations with missing data.
Jaccard Index (IoU): Commonly used in computer vision for object detection, the Jaccard Index can also be applied to text annotation tasks like span labeling. It measures the overlap between the annotations made by different annotators, with a higher value indicating greater agreement.
Use and application of IAA metrics:
- Guideline refinement: Low IAA values highlight areas of ambiguity or inconsistency in the annotation guidelines. By analyzing disagreements, annotators refine the guidelines to improve annotation consistency.
- Annotator training and calibration: IAA metrics are used to monitor annotator performance and identify individuals who require further training or calibration.
- Model evaluation: IAA can serve as a baseline for evaluating the performance of automated annotation models. A model that achieves an IAA score comparable to human annotators is considered to be performing well.
By incorporating these quality control metrics and techniques, text annotators ensure the creation of high-quality annotated datasets essential for developing and evaluating robust and reliable NLP models.
Best Practices While Using Quality Metrics to Improve Text Annotation
Applying quality assessment metrics effectively necessitates understanding their strengths and strategically using them in the text annotation workflow.
Here’s how to leverage these metrics for optimal results:
-
Metric selection aligned with annotation task: Different annotation tasks demand different evaluation criteria. For instance, while Cohen’s Kappa effectively measures inter-annotator agreement for categorical tasks like sentiment analysis, it falls short in capturing the nuances of complex tasks like relation extraction, where metrics like F1-score over relations are more appropriate.
-
Iterative improvement through continuous monitoring: Integrating quality assessment metrics into an iterative workflow is crucial. Initial annotation guidelines often require refinement.
By continuously monitoring metrics like Agreement Rate and Krippendorff’s Alpha on a subset of the data, ambiguities or inconsistencies in the guidelines are identified and addressed early on. This iterative feedback loop ensures consistent annotation quality throughout the project.
-
Leveraging metrics for targeted training: F1-score metrics for Named Entity Recognition (NER) tasks pinpoints specific entity types that annotators struggle with. This granular analysis enables targeted training, focus on areas needing improvement and ultimately leading to an accurately annotated dataset.
-
Combining metrics with qualitative analysis: While quantitative metrics provide valuable insights, qualitative analysis through annotator discussions and error analysis remains crucial. Analyzing disagreements revealed by low Jaccard Index scores for span annotation can uncover underlying linguistic ambiguities or guideline inconsistencies that quantitative metrics alone might miss.
By strategically integrating these practices, text annotation projects can leverage quality assessment metrics not just as evaluation tools, but as powerful drivers for continuous improvement, leading to higher quality annotated datasets and, ultimately, more robust NLP models.
HitechDigital enhanced a German construction technology company’s AI model.
HitechDigital enhanced a German construction technology company’s AI model by verifying, validating, and manually annotating complex text data from construction articles. Their two-step quality checking improved text classification accuracy, reduced turnaround time, and increased algorithmic performance.
Read full Case Study »Wrapping Up
The five text annotation metrics – Precision, Recall, F1-Score, Inter-Annotator Agreement, and Accuracy – provide a comprehensive framework for assessing the quality of text annotations. More than just benchmarks, these metrics are dynamic tools for continuous improvement.
Adapting metric selection to specific text annotation tasks, iteratively refining guidelines, and providing targeted training help you achieve a cycle of quality enhancement. This ultimately empowers you to build datasets of high accuracy and reliability, driving the next generation of NLP and AI applications that truly understand and respond to human language.
Understand User Intent
Utilize our intent annotation for accurate user insights.



