- AI models across industry applications depend on massive volumes of accurately annotated data for optimal performance.
- Annotation skills, tools and adoption of best practices are critical to meeting accuracy standards required for driving high-performing AI models.
- Defining clear strategies on best fit data annotation and labeling techniques is essential to meet AI project goals.
Artificial intelligence is redefining business strategies, taking them to new heights. The AI models powering those possibilities, however, depend on high-quality, accurately annotated data. According to Gartner, 80% of ML projects never reach deployment. A big reason for this is poor quality data annotation.
Implementation of effective data annotation strategies requires domain knowledge, the latest annotation tools and skilled human experts. When dealing with extremely high volumes of data, you need to fix priorities, processes, and resources to address general data labeling issues and those specific to your AI project. And to help you out with that, we look here at some tried-and-true data annotation strategies.
What is data annotation?
Data annotation is the process of labeling or tagging content attributes in text, photos, or videos so machine learning models and AI can understand their relationships and contextual relevance. This helps the AI model or MLM to assign weightage to data and logically process the content for action and prediction.
Benefits of high-quality data annotation for AI projects
A high-quality and meticulously annotated dataset helps to train an AI model through iterative data annotation and labeling processes and feedback loops. Accurate data annotation helps to:
Deal with diverse and unstructured data
Data exists in multiple forms such as text, image, video. This makes data annotation one of the most time-consuming and laborious parts of any AI project. It sometimes takes up to 70% of the overall project time. Data type-based annotation is vital for identifying elements useful for the AI model among diverse and unstructured data.
Serve different machine-learning algorithms
Machine learning is incorrectly and interchangeably used with artificial intelligence. However, it is an integral part of AI. It is used for solving business problems like regression, classification, forecasting, clustering, associations, etc. The ML algorithms receive and analyze input data to predict output values within an acceptable range.
Use a progressive workflow of training datasets
Real-time machine learning models require accurate training datasets. Annotating data ensures that the machine learning models are fed valid, accurate, and relevant training data.
Operate ML models with 100% accuracy
Without data annotation, ML models would be clueless about which data is good for input. It is only annotated and labeled data that determines the efficiency of ML models.
Offer a class of techniques
Data annotation works as a class of techniques and, based on the use case, can be used to identify elements of interest relevant to the goals of AI/ML models.
Solve the needs of different AI use cases
Annotation is the process of labeling objects in an image to make it recognizable to computer vision. Here are some types of image annotations used for computer vision in machine learning and AI.
Streamline AI/data science pipeline
Since AI and data science implementation involves the application of several machine learning applications, data annotation can help streamline the entire AI or data science pipeline. We used an automated image annotation workflow to accurately annotate 1.2M fashion images for a Californian technology company looking to scale its AI model. Find out how they saved time on data preparation and boosted annotation productivity by 96%.

The Future of Data Annotation: Key Trends and Innovations
- Industries globally are impacted by advancements in annotation.
- Smart tools and techniques enhance the performance of ML models.
- Synthetic data and multimodal annotation are trends that will dominate.
- Ethical data annotation practices ensure responsible AI development.
5 data annotation strategies to power your AI project
Training datasets and accurate data labeling are critical for any AI model. Implementing these 5 data annotation strategies will not only accelerate your AI projects but will save considerable time and costs.
1. Start with ground truth data annotation
The success of your AI model completely depends on your ground–truth dataset. ‘Ground truth data annotations’ or ‘ground truth labels’ refer to human-verified objects or information that can be accepted as facts.
When humans are involved in the classification and verification of data, the logical decision-making accuracy is high. And you get those accurate training datasets you need for a better project foundation. In ground truth data annotation, classification and verification by humans fast-tracks overall annotation and gives quality output.
2. Decide on the type of annotation your AI model requires
AI algorithms make complicated functions simpler, right from online shopping to streaming a web series. However, AI models need to be educated with accurately categorized and labeled datasets.
Here are some types of annotation you can use:
Image annotation:

Annotating images through captions, identifiers, and keywords as attributes to help the AI model perceive an annotated area as a different item. Algorithms then identify, understand, and classify these parameters and learn autonomously.
A Swiss food waste assessment solution provider used thousands of accurately annotated food images to power an AI model. It provided an instant analysis of food waste. The company has helped restaurants and hotels worldwide tackle food waste.
Video annotation:
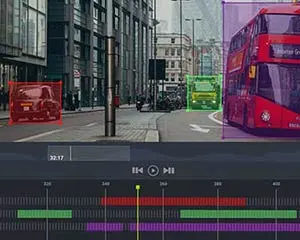
A fine combination of human annotators and automated tools are used to recognize motions or visuals and label target objects in video footage. This enables computer vision models to perform object location and tracking. The process can transform a minute of video footage at 30 frames per second into 1,800 images—arranged in a sequence.
Annotating live video streams helped a California-based data analytics company. They could use their AI model to better predict traffic congestion, prevent collisions, and improve road planning.
Text annotation:
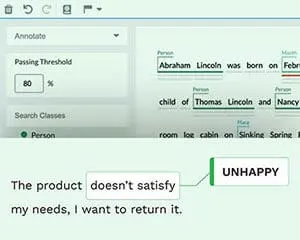
Human annotators analyze the content, discern the subject, intent, and sentiment within it, and classify it based on a predetermined list of categories. Text labelers assign categories to sentences or paragraphs in a given document or text. These range from consumer feedback to product reviews on e-commerce sites, and from mentions on social media to professional emails. Annotators identify intentions, concepts, and emotions like fun, sarcasm, anger, and other abstract elements.
2020 State of AI and Machine Learning report says that 70% of companies use text as a type of data for their AI solutions.
Text annotators make highly structured margins, which are usually invisible in human-readable content. These help computers to classify, link, infer, search, filter, and perform other functions. These identification parameters play a crucial role in text annotation.
Audio annotation:
Annotators must tag and label language, speaker demographics, dialects, mood, intention, emotion, and behavior for audio files. To make the audio files comprehensive, labelers annotate verbal cues and nonverbal cues, including silence, breaths, and background noise.
The value of the NLP market is expected to grow astronomically to $43 billion in 2025 from $3 billion in 2017.
Audio annotation is done using techniques such as timestamping, music tagging, and acoustic scene classification.
Semantic annotation:

The goal of semantic annotation is to make the content more easily searchable, understandable, and accessible for both humans and machines. As a critical component of the AI model, it improves the performance of chatbots and the accuracy of search relevance.
It is the process of adding metadata or labels to content in order to provide additional meaning and context. Annotators tag concepts like people, places, or company names within a document to help ML models categorize new concepts. Semantic annotation is used in a variety of contexts, including information retrieval, natural language processing, machine learning, and the semantic web.
3. Use relevant annotation techniques
Choosing which type of annotation to use depends on the data and annotation tools you are using. Let’s check out some annotation techniques:
-
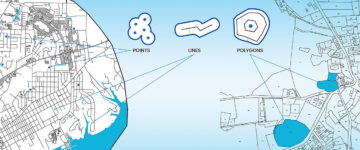
2D and 3D bounding boxes: Image annotation is done with the help of techniques such as bounding boxes and semantic segmentation for AI applications like facial recognition, robotic vision, autonomous vehicles, security. This technique helps immensely when annotating videos. It helps to implement concepts like location, motion blur, and object tracking.
-
Polyline: Leveraging this technique reduces the weakness of bounding boxes—the unwanted spaces. It is mainly used to annotate lanes on road images.
-
Polygons: Polygons are a universal choice for precise outcomes in tagging irregular shapes like human bodies, logos, or street signs. Accurately drawn boundaries around the object precisely show the shape and size, and help machines make better predictions.
-
Segmentation: Though similar to polygons, it is much more complicated. Polygons are used to select a few objects. However, segmentation can be used to label every pixel of every layer of similar objects. This leads to better and more precise results.
-
3D cuboids: When data annotation companies want to measure the volume of objects like vehicles, buildings, or furniture, they leverage 3D cuboids.
-
Text labeling: The techniques used here to label and tag text datasets include entity annotation, entity linking, text classification, intent extraction, phrase chunking, sentiment annotation, and linguistic annotation.
Accurately annotated text from customer emails improved the performance of a company’s NLP algorithm. Workflow designed to annotate in near real time (every 12 hours) it operates in the digital solutions, engineering, and business process management space. They assisted their clients in driving tailored strategies based on customer responses.
-
Landmark: This technique is mostly leveraged for facial and emotional recognition, human pose estimation, and body detection. Applications using data labeled by this technique can indicate the density of the target object within a specific scene.
4. Leverage the ‘Human-in-the-Loop’ (HITL) process
Humans in the loop, aka HITL, is a fine blend of human and artificial intelligence to build effective and efficient AI models. AI systems are trusted to make optimal decisions by addressing large and high-quality data sets. But nothing can surpass humans at recognizing patterns within small and poor-quality datasets. Leveraging the HITL approach, human annotators can validate a machine learning model’s output and refine AI for greater accuracy.
5. Adopt the latest data annotation tools and technologies
The global AI industry is undergoing significant changes. We can expect a decline in the manual annotation of large datasets. Either way, automated or manual data labeling is critical for improving the quality, accuracy, security, and usability of AI models.
But with the acceptance of synthetic approaches, machine learning trends using AI are moving toward:
-
Unsupervised learning: This will open new avenues for clustering and newer methods for unsupervised learning. Given the volume of data being produced, clustering algorithms are now becoming indispensable. They reduce manual input and provide faster results.
-
Contrastive and manifold learning: Usually effective and used for unlabeled datasets, this approach does not need labeled data, as these models perform encoding and embedding. Google has deployed contrastive learning for the Wikipedia platform.
-
Neuro-symbolic AI: Conventional approaches and modern data annotation techniques are increasingly reducing the need for labeling data. It has increased the dependency on statistical and knowledge frameworks. It saves a lot of time and effort for data labeling subject-matter specialists.
Conclusion
With an estimated data creation of around 464 exabytes daily by 2026, the need for data annotation for AI models is likely to skyrocket. On top of this, trends like Medical AI, Cloud, social media, Active learning, AutoML, Synthesis AI, and many more are making annotating and labeling data essential.
However, poor in-house tooling, labeling re-work, data discovery issues, and collaboration and coordination pose challenges.
These issues worsen when AI models need to scale quickly. Adapting and deploying a robust data annotation strategy is a must, as the volume of raw data to be labeled is increasing. Developing an AI model requires a significant volume of real-time data to perform well.