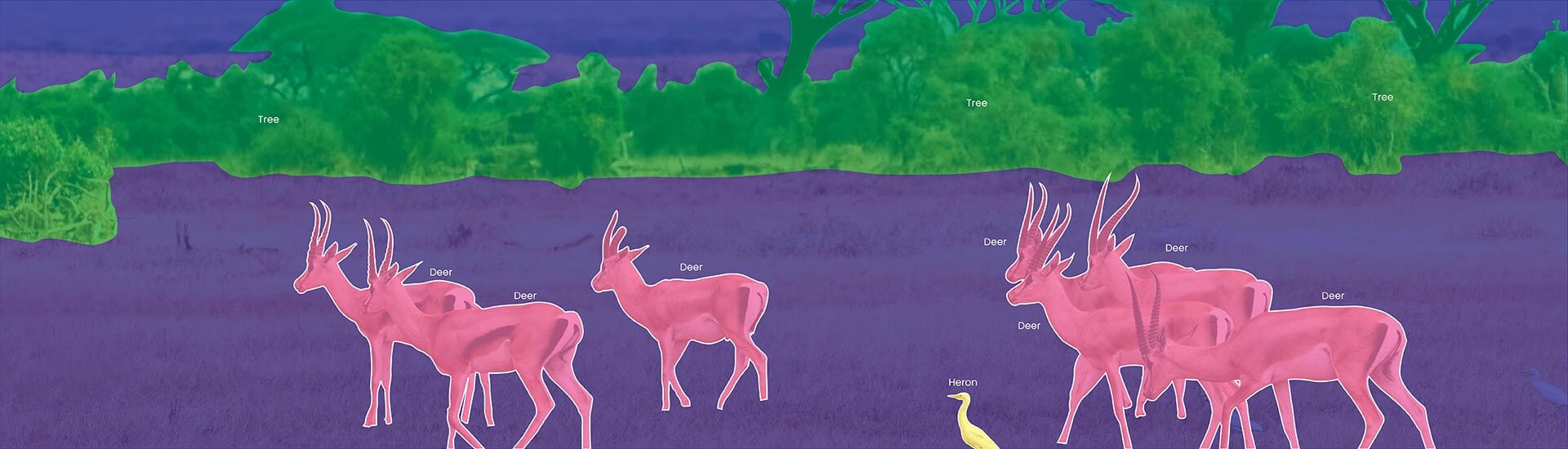

- Semantic image segmentation classifies each pixel, creating a detailed map of objects, unlike object detection, which uses bounding boxes
- Deep learning powers semantic image segmentation by utilizing techniques like weakly supervised/semi-supervised learning, active learning, and model-assisted annotation
- Advanced machine learning algorithms like U-Net and DeepLab significantly enhance segmentation accuracy and robustness by improving consistency, handling ambiguities, and mitigating subjectivity
Semantic image segmentation involves assigning a semantic label to each pixel. Deep learning image annotation has emerged as the dominant approach for semantic segmentation, leveraging convolutional neural networks (CNNs) to learn hierarchical features and generate precise segmentation masks.
Table of Contents
- What Is the Difference Between Object Detection and Semantic Segmentation?
- How to Choose the Right Annotation Tools for Semantic Segmentation with Deep Learning
- What Are Pixel-Level Labels in Semantic Segmentation and Why They Matter
- How Deep Learning Improves Semantic Segmentation in Computer Vision
- Semantic Segmentation Workflow: How to Annotate Images with Deep Learning
- Wrapping it up
Despite the progress made, semantic segmentation faces challenges such as class imbalance, domain adaptation, and real-time performance requirements. Techniques like data resampling, transfer learning, and efficient network designs are used to address these challenges and push the boundaries of semantic segmentation.
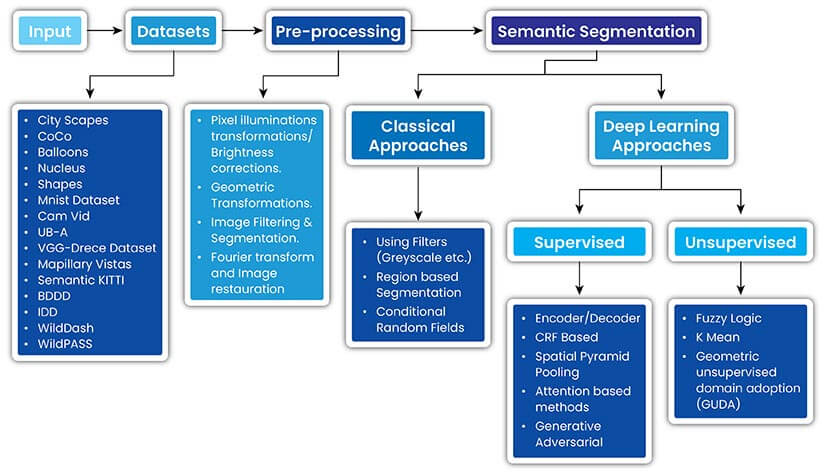
Training deep learning models for semantic segmentation requires large, annotated datasets, which can be time-consuming and labour-intensive to create. Here, we explore the concerns surrounding the annotation of training data for semantic segmentation and the deep learning techniques and methods used to address those concerns.
What Is the Difference Between Object Detection and Semantic Segmentation?
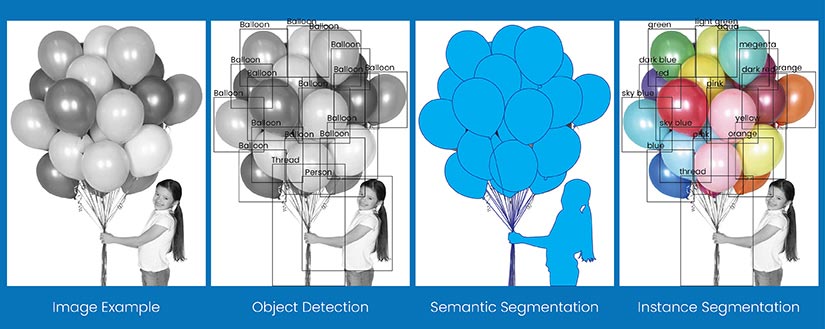
Most computer vision models are trained for object detection or semantic segmentation or for both. However, annotators are more familiar with object detection and can sometimes miss that semantic segmentation, being more granular has some extra needs in creating training datasets. Our object detection guide explores its versatility and impact across diverse applications in retail, autonomous driving, and agriculture.
Semantic segmentation assigns a class label to each pixel, creating a detailed map of objects. On the other hand, object detection identifies and localizes objects with bounding boxes. Segmentation offers pixel-level detail, useful for image classification tasks like medical imaging and autonomous driving, while object detection focuses on object localization, ideal for use cases like surveillance and retail analytics.
How to Choose the Right Annotation Tools for Semantic Segmentation with Deep Learning

When selecting an annotation tool for semantic segmentation, it is crucial to verify the tool’s functionality aligns with the specific requirements of the segmentation task, such as supporting polygons, pixel-level masks, and multiple object classes. Compatibility with common annotation formats, like COCO JSONs, Pascal VOC XMLs, or TFRecords, is essential for integration with deep learning frameworks.
Quality control features, including built-in validation, collaborative workflows, and progress monitoring, ensure the accuracy and consistency of the annotated image data.
Popular annotation tools for semantic segmentation include VGG Image Annotator (VIA), LabelMe, and Computer Vision Annotation Tool (CVAT).
CVAT, in particular, offers a web-based interface, supports various shape forms (e.g., polygons, polylines), and provides extensive export format options. Its collaborative features and ability to integrate with pre-trained models make it well-suited for team-based annotation projects.
Achieve Pixel-Perfect Accuracy for Your AI model
Empower your models with our precise semantic segmentation solution
What Are Pixel-Level Labels in Semantic Segmentation and Why They Matter
Pixel-level labels are detailed annotations where every pixel in an image is assigned a specific class, such as “car,” “tree,” or “road.” This labeling creates a dense, segmented map that helps deep learning models learn to distinguish and understand visual elements with fine-grained accuracy.
These annotations form the foundation of semantic segmentation, allowing AI systems to make pixel-perfect predictions.
Common Ways to Create Pixel-Level Labels:
- Manual annotation: Highly accurate, using tools like polygons or brushes—but time-intensive.
- Semi-automated tools: Use cues like edges or color similarity to speed up labeling.
- Weakly supervised methods: Start with rough labels and refine them using model feedback or corrections.
- Synthetic data generation: Automatically generate pixel-level labels from virtual environments; scalable but may require domain adaptation.
Why do they matter? Because pixel-level labels are the ground truth that trains semantic segmentation models to perform complex tasks—such as autonomous driving, medical imaging, or satellite analysis—with precision and reliability.
1.2M+ accurately annotated fashion images fuel high performing AI/ML model for Californian technology company
HitechDigital annotated over 1.2 million fashion images for a Californian technology company to enhance AI and machine learning models, ensuring high performance and scalability in their visual search capabilities.
Read full Case Study »How Deep Learning Improves Semantic Segmentation in Computer Vision
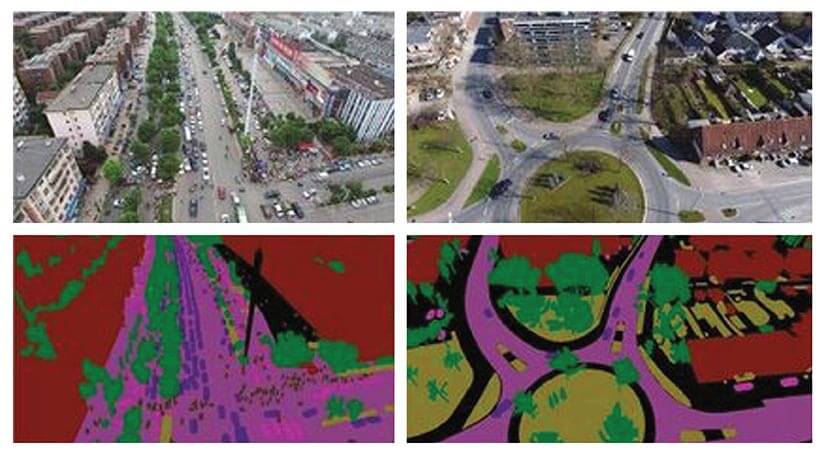
Deep learning techniques assist and improve image annotation for semantic segmentation on multiple levels, including the saving of time and costs, increasing consistency and quality control, eliminating ambiguous boundaries caused by occlusions, shadows or low contrast, and helping to deal with subjectivity.
Types of Semantic Segmentation Annotations Used in AI Training Data
Semantic segmentation relies on various types of image annotation techniques. The most common techniques include:
- Polygonal annotations: Polygons are used to precisely delineate object boundaries by connecting vertices along the object’s contour. This allows for accurate representation of complex shapes but can be time-consuming for irregular objects.
- Pixel-wise masks: Each pixel in the image is assigned a class label, resulting in a dense segmentation mask. This approach provides the most fine-grained annotation but requires significant manual effort, especially for large datasets.
- Superpixels: The image is divided into small, homogeneous regions called superpixels, which are then assigned class labels. This technique reduces the annotation effort by grouping similar pixels but may lose some fine details.
- Scribbles and points: Annotators provide sparse labels by drawing scribbles or placing points on objects of interest. These annotations are then propagated to the entire object using techniques like graph cuts or deep learning-based interpolation.
How Deep Learning Supports Semantic Segmentation Training Data Preparation
Deep learning techniques in image segmentation annotation help by:
- Reducing annotation effort: Weakly supervised and semi-supervised learning approaches leverage sparse annotations, such as image-level labels or scribbles, to generate dense segmentation masks. This significantly reduces the manual annotation burden.
- Improving consistency: Deep learning models can learn to generate consistent annotations by learning from large-scale datasets and capturing intricate patterns. Techniques like data augmentation and transfer learning further improve the model’s robustness and generalization.
- Handling ambiguous boundaries: Deep learning architectures, such as encoder-decoder networks (e.g., U-Net) and Atrous convolutions (e.g., DeepLab), can effectively capture multi-scale context and refine object boundaries, even in challenging scenarios.
- Mitigating subjectivity: By training on diverse datasets annotated by multiple annotators, deep learning models can learn to average out subjective variations and produce more consistent and reliable segmentation results.
Semantic Segmentation Workflow: How to Annotate Images with Deep Learning
Data Collection and Preparation
The images in the initial dataset should capture various object scales, orientations, lighting conditions, and occlusions to improve the model’s robustness. Preprocessing steps like resizing, normalization, and augmentation (e.g., flipping, rotation) help standardize the input and expand the dataset.
For semantic segmentation, it’s important to ensure pixel-level alignment between the images and their corresponding segmentation masks. Any misalignment can lead to inaccurate ground truth and degrade model performance.
Techniques like edge detection and superpixel segmentation are used to refine the alignment and preserve object boundaries.
Accomplish Unparalleled Image Understanding
Leverage our semantic segmentation techniques for accurate class labeling
Initial Model Training
Selecting the right architecture is key for semantic segmentation. Fully Convolutional Networks (FCNs) and encoder-decoder architectures like U-Net use convolutional layers to capture hierarchical features and upsampling to generate high-resolution segmentation masks.
Leveraging pre-trained models, such as those trained on ImageNet for classification, can significantly speed up convergence and improve accuracy, especially when training data is limited. The pre-trained weights serve as a good initialization for the convolutional layers, which can then be fine-tuned for the segmentation task.
Loss functions like cross-entropy and Dice loss are commonly used for semantic segmentation. Cross-entropy loss measures the pixel-wise classification error, while Dice loss focuses on the overlap between the predicted and ground truth masks. Optimization algorithms like Adam or SGD with momentum help minimize these losses during training.
Monitoring the model’s performance on a validation set during training is essential to avoid overfitting and select the best model checkpoint. Metrics like mean Intersection over Union (mIoU) and pixel accuracy provide a quantitative measure of segmentation quality.
Model-Assisted Annotation
Deep learning models can significantly accelerate the image labeling process by generating initial segmentation masks. These masks serve as a starting point for human annotators, who can then refine and correct the annotations as needed.
There are several types of model-assisted annotation:
- Batch inference: The trained model is applied to a batch of unlabeled images to generate segmentation masks. Annotators review and correct these masks.
- Interactive segmentation: The annotator provides a few clicks or scribbles on the object of interest, and the model generates a segmentation mask based on these inputs. The annotator can iteratively refine the mask by providing additional inputs.
- Uncertainty-guided annotation: The model’s predictive uncertainty is used to identify regions where it is less confident. Annotators focus on these regions to provide more accurate labels and improve the model’s performance.
Model uncertainty is estimated using techniques like Monte Carlo dropout or ensemble methods. Regions with high uncertainty are more likely to contain errors or ambiguous boundaries, making them prime candidates for manual review and correction.
Active Learning Iteration
Active learning is an iterative process that selects the most informative samples for annotation, rather than randomly selecting samples. This helps focus annotation efforts on the most challenging or uncertain regions, leading to more efficient use of resources.
The active learning cycle involves:
- Training an initial model on a small, labeled dataset.
- Applying the model to a pool of unlabeled image data and selecting the most informative samples based on an acquisition function (e.g., uncertainty, diversity).
- Annotating the selected samples and adding them to the training set.
- Retraining the model on the expanded dataset and repeating the process.
Common active learning strategies for semantic segmentation include:
- Uncertainty sampling: Selects samples with the highest predictive uncertainty.
- Diversity sampling: Selects samples that are most diverse in terms of their features or predictions.
- Query-by-committee: Selects samples that cause the most disagreement among an ensemble of models.
By focusing annotation efforts on the most informative samples, active learning can significantly reduce the amount of labeled data needed to train an accurate segmentation model.
Reviewing for Quality Assurance
Manual review and correction are essential for ensuring training data quality. Annotators carefully inspect the segmentation masks for accuracy, consistency, and adherence to the annotation guidelines.
Automated quality checks help identify potential errors or inconsistencies in the annotations. Techniques like consistency checks (e.g., ensuring all pixels are labeled), format checks (e.g., verifying mask dimensions), and statistical checks (e.g., detecting outliers in class distributions) can flag issues for further review.
Metrics like mIoU, pixel accuracy, and F1 score can be used to assess the quality of the annotations. These metrics provide a quantitative measure of the agreement between the annotated masks and the ground truth, helping identify areas for improvement.
Final Model Training
With the annotated dataset, the final model training phase focuses on refining the model’s performance and generalization. This involves:
- Hyperparameter tuning: Systematically searching for the best combination of hyperparameters (e.g., learning rate, batch size) to optimize performance and ensure model accuracy.
- Incorporating advanced techniques: Integrating techniques like attention mechanisms, which help the model focus on relevant regions, or multitask learning, which simultaneously learns related tasks (e.g., segmentation and edge detection) to improve generalization.
- Model deployment and testing: Deploying the trained model to a production environment and testing its performance on real-world data. This helps assess the model’s robustness and identify any potential issues or biases.
By iterating on the model training process and incorporating advanced techniques, the final semantic segmentation model achieves high accuracy and reliability, enabling its use in various applications like autonomous driving, medical image analysis, and remote sensing.
Wrapping it up
Deep learning has revolutionized the field of semantic segmentation primarily in three ways. Leveraging weakly supervised and semi-supervised learning, employing active learning strategies, and utilizing model-assisted annotation to generate initial segmentation masks.
Advancements in deep learning architectures, such as encoder-decoder networks like U-Net and Atrous convolutions in DeepLab, have significantly improved the accuracy and robustness of semantic segmentation models. Today, semantic segmentation is used in computer vision to capture multi-scale context, refine object boundaries, and handle challenging scenarios like occlusions and varying object scales, and improve the perceptions of high-performing models.
Unlock Detailed Image Classification for your Computer Vision projects
Enhance your training data with our expert semantic segmentation services




